資料ダウンロード
設計開発におけるデータマイニング活用のススメ
最適設計支援ツール「Optimus」によるデータマイニング
CAEのあるものづくり Vol.20|公開日:2014年4月
目次
- はじめに
- Golinskiの減速機の設計問題
- データマイニングの実施
- 結果とまとめ
- 補足
- おわりに
はじめに
近年、解析規模と解析回数が飛躍的に増加し、解析結果の評価検討にも多くの時間が費やされています。さらに、効率的且つ効果的なCAEの活用と運用への要求も年々高まってきています。そこで、有効な解決方法としてデータマイニングの活用をお勧めします。
データマイニング( 英語: Data mining)とは、統計学、パターン認識、人工知能等のデータ解析の技法を大量のデータに網羅的に適用することで知識を取り出す技術(ウィキペディアより引用)です。設計開発においてデータマイニングを活用するということは、①CAEを活用することで、データマイニングに必要な複数のサンプルデータを取得する。②CAEによって得られたデータをデータマイニングにより分析し、知見を得て、効率よく設計検討を行なう。という2つのステップを実施することになります。
設計開発においてデータマイニングを活用するメリットをまとめると、次のようなものが挙げられます。
- 複数の解析結果から有益な情報を抽出し、設計案の妥当性評価とより良い設計案の提案が期待できる。
- 整理できていない大量のデータを有効活用できる。
- 有効な設計変数を見つけることで、試行錯誤の回数を減らし、効率的に最適設計を決定することができる。
- ポスト処理でデータを可視化することで、対象の問題についての情報共有や理解が促進される。
本稿では、最適設計支援ツールOptimusのデータマイニング手法の紹介と共に、実際に適用事例を交えてご紹介します。
Golinskiの減速機の設計問題
本事例ではGolinskiの減速機の設計問題(図1)を対象として、データマイニング活用の一例をご紹介します。Golinskiの減速機では、出力値(制約条件となるパーツの配置、変位、応力や目的関数となるギヤボックスの体積)が設計変数である減速機の各寸法を変数とした関数で表されています。
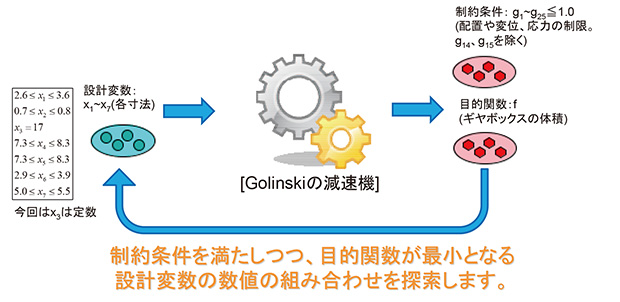 図1 Golinskiの減速機の設計問題の概要
図1 Golinskiの減速機の設計問題の概要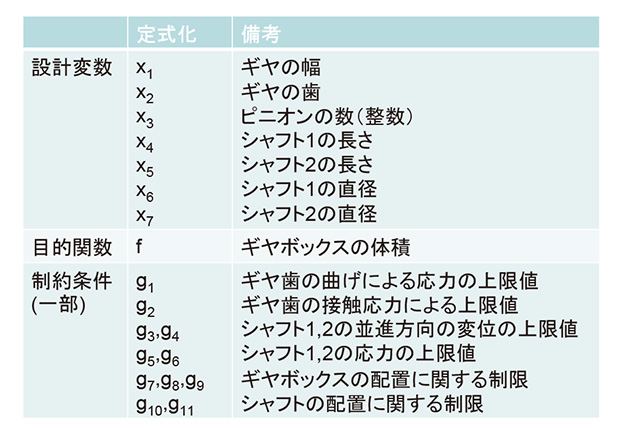 図1 Golinskiの減速機の設計問題の概要
図1 Golinskiの減速機の設計問題の概要詳しくは参考文献(最適設計ハンドブック -基礎・戦略・応用- (山川宏, 2003, pp. 66-67))をご覧ください。そのため、特別な解析プログラムが無くても計算を行なうことができ、どの設計変数と、どの出力値に相関があるのかが、関数の項から確認することができます。但し、本事例では設計変数と出力値の関係が関数として明らかでない状況を想定し、データマイニングによる分析をおこないます。最終的にデータマイニングの結果が正しいのかどうか関数を確認することで検証を行います。
まずは、ご自身でこの問題に取り組む状況を考えてみてください。どのように取り組んでいけばよいのか?これだけ多くの制約条件はどのようにすれば満たせるのか?どの設計変数を変更すると効果的なのか?どのように設計変数の組み合わせを決めたらよいのか?・・・。データマイニングを実施することで、これらの疑問を解決していきます。
データマイニングの実施
この設計問題の目的は定められた設計変数の範囲で、減速機の体積fを最小にすることです。ただし、この減速機の仕様として制約条件を満たしていなければなりません。闇雲に設計変数の数値を変えて試行錯誤をしても、手間がかかるばかりか仕様を満たす設計案が得られないかもしれません。そこで、データマイニングによって設計変数と制約条件、目的関数の関係を把握すれば、設計検討のための指針を得ることができます。具体的には、出力値に対して、どの設計変数が寄与しているのかを把握します。寄与している設計変数が分かると、制約条件を満たしたり、目的関数をより小さくしたりするためには、どの設計変数の数値を変更すればよいのか分かります。そのため無駄な検討作業を減らし、工数の削減につながります。
それでは前節のGolinskiの減速機の設計問題について、データマイニングを実施していきます。データマイニングには様々な手法や、取り組み方が存在します。今回は一例として、以下のような流れで実施していきます。
①実験計画法によるサンプリング
実験計画法を用い、設計空間全体を均一にサンプリングするための設計変数の組み合わせを決定します。サンプリングの目的は、設計空間内における設計変数と出力値の関係を把握することです。そのため、各設計変数の上下限値の間で均等にサンプリング点を配置し、その各点における出力値がどのような応答を示すか把握するデータが必要となります。
②応答曲面モデルの作成
実験計画法の結果は離散的なため、応答曲面モデルを作成し、連続的な関数として表します。連続的な関数とすることで、結果を分かりやすく可視化したり、近似計算に利用したりすることができます。
③ポスト処理による結果検討
結果検討にはデータマイニングのための特別なポスト処理を活用します。複数のデータを表示するのに適したポスト処理を活用することで、結果の分析や理解が容易になります。
* ここで使用している手法やポスト処理が全てではありません。また、本稿では各手法の詳細やその他のポスト処理については触れませんので、Optimusのウェブサイト (https://www.cybernet.co.jp/optimus/) をご覧ください。参考図書などもご紹介しています。
3.1 実験計画法によるサンプリング
実験計画法の手法にはラテン超方格法という手法を使用しています。指定したサンプリング点数を設計変数の範囲において、なるべく均等に配置することができます。サンプリングデータに関しては相関散布図を利用することで、その概観を掴むことができます。制約条件を満たしているサンプリング点が少なく…
関連情報
関連する解析事例
MORE

関連する資料ダウンロード
MORE-

実測 × 解析で基板の熱変形問題を解決!基板反り現象の高精度シミュレーション
~エスペック(株)×サイバネットシステム(株)の連携ソリューション~
-

【全記事】CAEのあるものづくり vol.42
ユーザー様インタビュー記事7件を1冊に集約した保存版
-

誤差との上手なつきあい方 ~流体解析の計算誤差~ (完全保存版)
誤差との上手なつきあい方 前編・後編 を1冊にまとめた保存版 PDF
-

非線形解析の最大強度評価はAnsys LS-DYNAで解決!
~Ansys LS-DYNAで解決!最大荷重評価のボトルネック~
-

事例でご紹介!流体解析分野のエンジニアリングサービス ~解析業務の委託・立ち上げ支援・カスタマイズによる効率化など~
-

はんだ濡れ上がり形状予測解析で電子機器の信頼性向上
~Ansys LS-DYNAで電子機器の信頼性向上に貢献~
-

Ansys ユーザーのための PyAnsys 完全ガイド
Pythonで加速するCAEワークフロー
-

共振回避だけで終わらせない振動解析の進め方を解説(周波数応答・時刻歴まで)
~Ansys Mechanicalで実現する高度な製品開発~