電気機器の製造データ分析によりリアルタイム監視による不良検知を実現
導入事例

IoT/デジタルツイン構築サービス


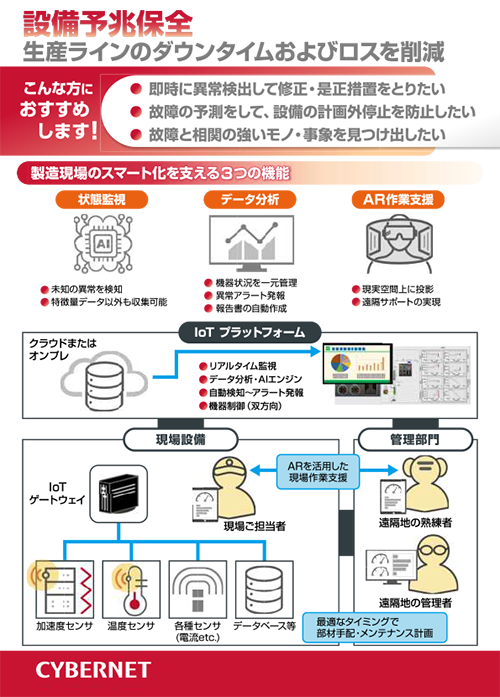
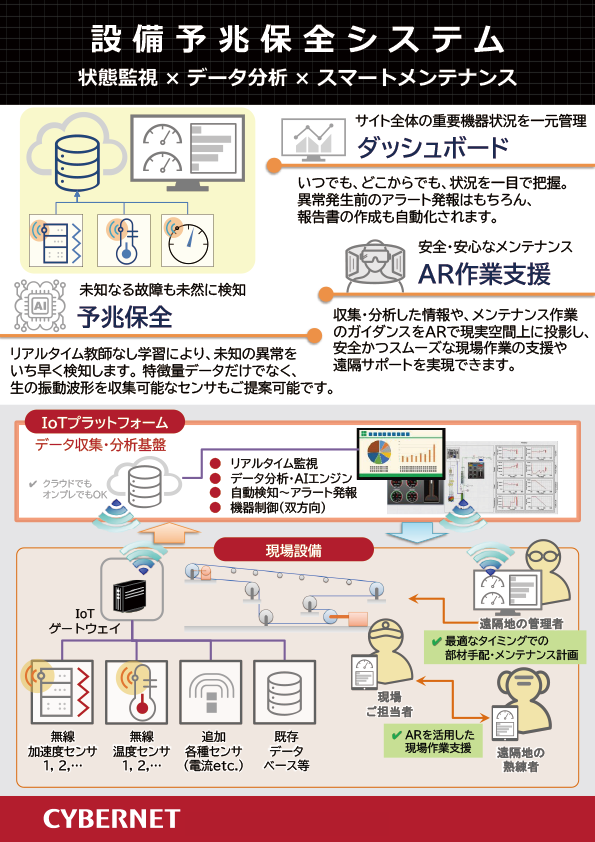
IoT で設備や各機器の状態をリアルタイムに監視し、より最適な稼働状態の管理を実現します。
さらにデジタルツインで仮想と現実の融合による予兆保全が可能に。生産性を飛躍的に向上させます。
BIGDAT@Analysisは多変量IoTデータをそのまま使って現場の方にも分析・把握できる可視化ツールです。IoTデータを活用したトラブルの予兆監視も可能になります。
Gemini eye は発生頻度が低く収集が大変な不良品ではなく、良品のみで学習が可能な外観検査 AI です。不良品を発生されることなく、少量のデータからも学習が可能。不良品が流れてくると「いつもと違う」と教えてくれます。
「IoT=IT×OT」と位置付け、IT技術を駆使した製造技術(OT)の改革を目指します。 センサデバイスの選定からシステムの開発・構築・運用までワンストップでご支援可能。