コラム
自動車業界のAIモデル開発:CAEデータ×3D深層学習でデータ収集の壁を超える

最初の蒸気機関が登場して以来、産業界はつねにプロセス改善を探求し続けてきました。その終わりのない追求を支えているのが、経済競争におけるダーウィン的な進化の原理です。新たなイノベーションを取り入れることは、競争を一歩リードする最善の方法といえます。
近年、人工知能(AI)はそうしたイノベーションの中でも特に大きな進歩として存在感を高めています。好むと好まざるとにかかわらず、AIは今後も社会に定着していくでしょう。だからこそ、私たちはAIを受け入れて(少なくともその影響を理解して)、乗りこなしていく必要があります。
自動車業界におけるAIの重要な活用分野の一つが、予測モデルの開発です。予測分析は、企業が製品やプロセスに関して、より適切な意思決定を行う助けとなります。こうしたモデルは多くの場合、機械学習(ML:マシンラーニング)アルゴリズムを用いて構築されます。
ただし、機械学習のセットアップには、一般に大量のデータが必要です。そのため、自動車関連企業がこれを導入する際には、AIモデルの学習に利用できるデータの量と質の制約が発生します。こうしたデータを収集し、管理することは、多くのエンジニアリングチームにとって大きな課題となり得ます。
本記事では、データ収集とデータ管理に関する実践的な方法をご紹介し、自動車業界における革新と進歩を後押しします。これにより、企業は精度高く信頼性のあるAIモデルを構築しやすくなります。
AIモデルとは
本記事においてAIモデルとは、機械学習アルゴリズムを用いて構築された、ある課題やタスクの数学的表現を指します。言い換えれば、データから学習し、その学習結果――すなわち入力データと出力データの相関関係――にもとづいて予測や意思決定を行うプログラムです。
AIモデルは、大規模なデータセットを使って学習させることができます。ここでいうデータセットとは、入力と出力の各データ点を表すサンプルの集合です。学習済みのAIモデルには、データを分類させることもできますし、本記事で主に扱うように、新たに与えられたデータに対して予測をさせ、その結果を割り当てるといった用途にも活用できます。
AIと機械学習モデルの関係
人工知能と機械学習モデルは密接に関係していますが、その対象範囲は異なります。人工知能は、機械学習を含む多くの技術を包含する広い概念です。一方で機械学習は、データから学習し、その結果にもとづいて予測や意思決定を行うモデルを構築することに焦点を当てた、AIの一分野です。
つまり、すべての機械学習モデルはAIモデルに含まれますが、すべてのAIモデルが機械学習モデルであるとは限りません。
では、こうしたモデルはどのように実運用へ展開していくのでしょうか。
AIモデルの導入
「AIモデルを導入する」とは、そのモデルを実際のアプリケーションの中で利用できる状態にすることを意味します。通常は、モデルを他のシステムやアプリケーションに統合可能なソフトウェアコンポーネントとしてパッケージ化する作業が含まれます。また、実運用にあたっては、モデルが高い精度と効率で動作するように、テストやチューニングを行うことも重要です。
AIモデルは、ビジネスや金融、医療、輸送など、さまざまな分野でいっそう重要な役割を担うようになっています。AIモデルを活用することで、組織はより正確な予測を行い、反復的または複雑な作業を自動化し、意思決定プロセスを改善することができます。そのため、AIモデルを開発し導入する能力は、企業や組織にとって重要な競争優位性といえます。
そして、機械学習による予測の可能性を実際に活かせる組織と、「PoC(概念実証)」の段階で止まってしまう組織とを分ける大きな要因になるのが、モデル学習に用いるデータをどのように収集するのかです。
データ収集とAIアルゴリズム選択プロセス

データ収集プロセスは、精度の高いAIモデルを構築するうえで極めて重要な要素です。質の高いデータを確保するためには、まずデータソースを特定し、どのような種類のデータが必要なのかを明確にしなければなりません。
データソースには、社内/社外、構造化データ/非構造化データ、2D画像/3D画像/テキストなど、さまざまな形態があります。データソースを特定した後は、効率的かつ正確かつ安全な方法でデータを収集することが次の課題となります。また、収集したデータに偏りがなく、対象となる母集団を適切に代表していることも確認する必要があります。
そのために、現場では以下のようなさまざまなデータ収集手法が用いられます。
・AIによって生成されたデータ(合成データ)を活用
これは、AIモデルを用いて実世界のデータに近い性質を持つデータを生成する手法です。現実のデータが十分に得られない場合や、実データの収集が困難または高コストな場合に有効です。ただし、適切に実施しなければ、偏りを含んだデータを生み出してしまうおそれがあります。
・外部リソースから収集したデータを利用
ソーシャルメディア、Webスクレイピング、オンライン調査といった外部ソースからデータを収集する方法ですが、この記事で想定しているようなエンジニアリング用途にはあまり適していません。
・技術パートナーから収集したデータを利用
既存のデータウェアハウスやシステムインテグレーターなどからデータを入手する方法です。ただしこの場合、データの所有権、さらにはそのデータを用いて構築された予測分析モデルの権利を誰が持つのか、という問題が生じます。
・既存の社内データベースから収集したデータを利用
企業内のPLM(製品ライフサイクル管理)などからデータを持ってくる方法です。技術パートナーデータに比べて知的財産を確保しやすい安全な手段ですが、利用可能なデータの質と量には限界があります。
データ処理とクリーニング
データ収集は、精度の高いAIモデル構築に向けた一工程にすぎません。データを収集した後には、ノイズや誤りを取り除くための前処理とクリーニングが必要になります。これは、収集したデータをAIモデルが利用できる形式へと変換する作業です。
このプロセスでは、3D Deep Learningベースの予測モデルは優位性があります。こうしたモデルは生の3D CADデータやCAEデータを直接利用できるため、前処理の工程を省略でき、時間と労力の削減につながるのです。
AIアルゴリズム
データの前処理を終えた後は、予測モデルを構築するために適切なAIアルゴリズムを選定する段階に入ります。アルゴリズムの選択は、使用するデータの種類と、最終的に得たい結果によって決まります。
代表的なアルゴリズムとしては、次のようなものがあります。
- 決定木
- ロジスティック回帰
- サポートベクターマシン(SVM)
- ニューラルネットワーク(この点については後ほどさらに詳しく触れます)
こうしてモデルを構築した後は、その精度と信頼性を確保するために、検証とテストを行わなければなりません。
以上のように、データ収集は、精度が高く適切に定義されたAIモデルを構築するうえで不可欠な要素です。
自動車業界における機械学習
自動車業界ではAIモデルの活用が急速に進んでおり、設計・エンジニアリング・製造・流通など、さまざまな領域で大きな改善がもたらされています。
その一方で、業界におけるAI導入には大きな課題もあります。精度の高い予測モデルを構築するためには、大規模な学習用データセットが必要です。さらに、既存モデルをクラウド上で効率的に学習させたり、計算資源配分を最適化することも重要になってきます。
従来の機械学習モデルとその限界
線形判別分析やロジスティック回帰モデルといった従来の機械学習モデルは、これまで自動車業界における予測分析で広く活用されてきました。たとえば、速度、気象条件、ドライバーの挙動といった独立変数をもとに、車両故障や事故の発生確率を予測することができます。
しかし、こうしたモデルは、特定のデータセットのパラメータに強く依存しているため、精度や適用範囲に限界が生じやすいという問題があります。そこで、数学やデータサイエンスの専門家たちは、より幅広い入力データを扱える深層ニューラルネットワークを開発してきました。
従来の機械学習モデルとその限界
線形判別分析やロジスティック回帰モデルといった従来の機械学習モデルは、これまで自動車業界における予測分析で広く活用されてきました。たとえば、速度、気象条件、ドライバーの挙動といった独立変数をもとに、車両故障や事故の発生確率を予測することができます。
しかし、こうしたモデルは、特定のデータセットのパラメータに強く依存しているため、精度や適用範囲に限界が生じやすいという問題があります。そこで、数学やデータサイエンスの専門家たちは、より幅広い入力データを扱える深層ニューラルネットワークを開発してきました。

自動車業界におけるAIと画像認識
深層ニューラルネットワークは、こうした多様なデータソースに含まれるパターンを認識できるよう学習させることで、自動運転車は複数の情報を統合したうえで意思決定を行えるようになります。
さらに、AIモデルの予測性能は継続的に向上させることが可能です。その結果、予測精度が高まり、自動運転車は周囲の環境変化に対してより柔軟かつ迅速に対応できるようになります。
従来の機械学習の限界を超えるアプローチ
これまで見てきたように、自動車業界において深層ネットワークを開発・導入することは、従来の機械学習モデルの限界を越える一つの手段となります。深層学習モデルは、より幅広い入力データを扱えるため、変化する条件にも適応しやすく、高精度な予測モデルの構築を可能にします。
一方で、従来の機械学習モデルは、特定のデータパラメータに基づいて学習するよう設計されているため、1つの教師あり学習モデルを訓練するために収集できるデータの多様性が制限されがちです。
そのため、新しいプログラムが始まるたびに予測モデルをゼロから作り直す必要があり、さらに新たな設計キャンペーンごとに、モデル学習用のデータセットも再生成しなければなりません。
この課題に対処するために、業界では3D深層学習ベースの予測モデルと呼ばれる特定のAIモデル群が活用されるようになっています。
深層ニューラルネットワークとは
データサイエンティストたちは、入力として与えられる多様なデータを処理できる、深層ニューラルネットワークを開発してきました。これは人工ニューラルネットワークの一種であり、AIモデルの中でも特に高度な表現力を持つものです。
深層学習モデルは、高度なデータ解析技術を用いて、データ内のパターンを見いだします。こうしたモデルは、多様な幾何学的パラメータ化やトポロジーをまたいで学習させることができるため、利用可能な学習データの母集団を大きく広げることができます。
この柔軟性によって、データサイエンティストは、さまざまなトポロジーやパラメータ化にまたがって利用できるモデルを開発しやすくなります。
深層ネットワークの発展は、自動車業界におけるAIモデルの可能性を大きく押し広げました。データ収集と分析に、より柔軟なアプローチをもたらし、その結果として、予測モデルの開発に活用できる学習データの範囲も大きく広がっているのです。
CAEシミュレーション

CAEとは「Computer-Aided Engineering」の略で、コンピュータソフトウェアを用いて物理システムの挙動をシミュレーションし、3次元空間上の複雑な問題を解くための技術です。デジタルツインの概念が広がるなかで、CAEはIndustry 4.0においてますます重要な存在となっています。
CAEチームが生み出すすべてのシミュレーション結果は、深層学習によって再利用することが可能です。これにより、データ収集にかかる労力を削減できるだけでなく、AIモデルの柔軟性も高めることができます。
CAEの大きな利点の一つは、AIモデルの開発に利用できる膨大なデータを生成できる点にあります。こうして得られたデータセットは、機械学習アルゴリズムの学習に活用でき、製品設計の最適化、性能向上、コスト削減に役立つ予測モデルの構築につなげることができます。
畳み込みニューラルネットワークによる機械学習
Neural Conceptが開発しているような深層ネットワーク、すなわち「畳み込みニューラルネットワーク(CNN)」は、CAEシミュレーションによって生成されたデータを扱うのに特に適しています。これは、画像処理、すなわちコンピュータビジョンで用いられるAIモデルに近い考え方に基づいています。
CNNは、3D CADデータやCAEデータのような大量かつ複雑なデータを扱うことができ、しかも設計ごとの特定のパラメータ化に依存しません。そのため、CNNはCAEを補完するAI駆動型シミュレーション基盤として活用でき、場合によっては設計者にとって新たな選択肢にもなり得ます。
つまり、同じモデルで複雑な問題を扱いながら、多様な幾何学的パラメータ化やトポロジーにまたがって学習を進めるなど、はるかに高い柔軟性を実現できるのです。
さらにCNNは、データ内のパターンや相関関係を学習し、それにもとづいて予測を行ったり、新しい設計案を生成したりすることも可能です。
総じていえば、CAEシミュレーションとCNNの組み合わせは、エンジニアリング分野におけるAIモデル開発のための強力な手段です。CAEチームが得たシミュレーション結果を再利用することで、データサイエンティストはデータ収集に必要な労力を大幅に削減でき、同時にAIモデルの柔軟性も高めることができます。その結果、より効率的でコスト効率の高い製品設計が可能になり、最終的には製品の性能や安全性の向上にもつながります。
3D深層学習ベースの予測モデル
業界でAIを活用した設計ワークフローの導入が進むにつれて、企業は精度が高く、適切に定義されたデータ管理ワークフローを整備する必要があります。自動車業界でAI手法を導入する際にしばしば課題として認識されるのが、予測モデルの学習に利用できるデータ量です。
機械学習は大規模なデータセットから大きな恩恵を受けますが、こうしたデータセットを収集すること自体が、予測モデルを大規模展開しようとするエンジニアリングチームにとって大きなハードルとなります。この課題を緩和するのが、3D深層学習ベースの予測モデルという特定のAIモデル群です。
これらのモデルは、生の3D CADデータやCAEデータをそのまま利用し、設計上の特定のパラメータ化に依存しません。つまり、同一のモデルを用いて、多様な幾何学的パラメータ化やトポロジーにまたがる学習が可能であり、より大規模なデータプールを活用できるのです。
最終的には、あらゆるCAEチームが生み出したシミュレーション結果を、これらのモデルの中で再利用できるようになります。その結果、モデルの柔軟性は大幅に向上し、データ収集に必要な労力も劇的に削減されます。
横断活用型アプローチと古典的アプローチの基本的な考え方
自動車分野の具体的な応用例に入る前に、まずはデータ利用効率について、一般的な観点から整理しておきます。
従来のAIモデルは、非常に特殊なパラメータ化に基づいて学習されます。例えば、スポイラーのない自動車モデルのような、長さ、厚さ、半径などのパラメータが定義された特定の「プロジェクト」を想像してみてください。このとき、入力変数と出力変数の相関関係は、推論モデル――すなわちAIベースの予測分析モデル――によって表現できます。このモデルは、サロゲートモデルとも呼ばれ、データ生成に用いたCAEモデルの挙動を近似的に再現するものです。
こうしたモデルは線形回帰より高度ではあるものの、実際にはそのプロジェクト固有のパラメータ空間、いわばその「箱」の中に特化した回帰モデルになります。
つまり、このような一般的なAIモデルは、異なるトポロジーや異なるパラメータ化をまたいだ利用ができません。その結果、特定のタスクを実行する単一モデルを学習させるために収集できるデータの多様性は制限されてしまいます。
したがって、2つ以上のプロジェクトが存在する場合、それぞれについて個別のサロゲートモデルが必要となり、図に示されているように、モデルはプロジェクトごとに分断されます。
各プロジェクトごとに個別のサロゲートモデルを構築するアプローチでは、最終的に、分断された複数のサロゲートモデルが並立する状態になります。
より具体的にいえば、新しいプロジェクトが始まるたびに予測モデルをゼロから構築し直すことになり、新しい設計キャンペーンのたびに、学習用データセットも再生成しなければなりません。このようなサイロ化したアプローチでは、自動車業界における応用可能な範囲が制約されてしまいます。
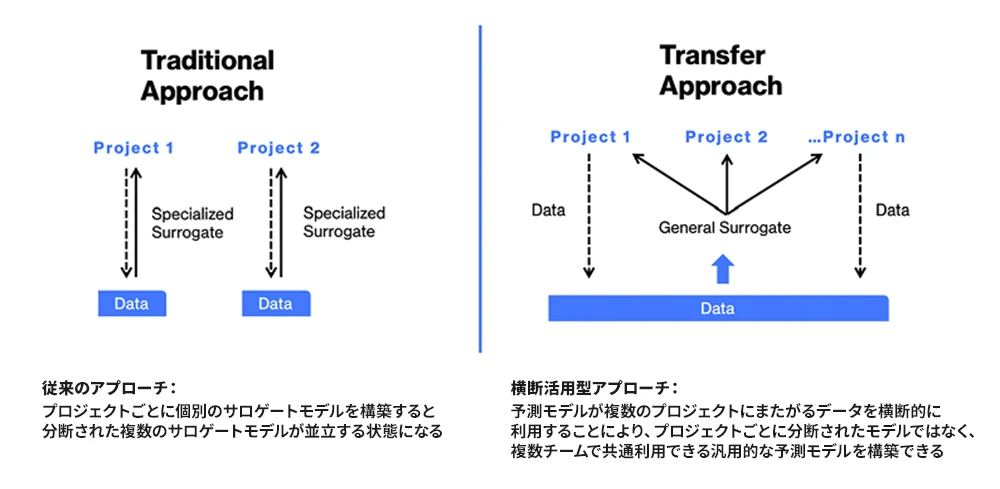
横断活用型アプローチの効果をどう捉えるか
Neural Conceptが提唱する横断活用型アプローチは、自動車業界をはじめとする多くの産業にとって、非常に示唆に富む考え方です。図が示すように、3D深層学習を用いたプロジェクト横断・累積型のアプローチは、年間に2件程度のプログラム(プロジェクト)があれば、プロジェクトごとに必要となるシミュレーション数の面で効率性を発揮し始めます。
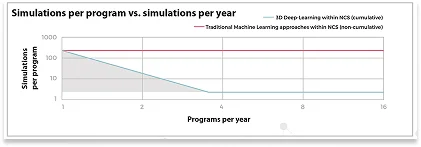
右の図はNeural Conceptがこれまでに蓄積してきた経験に基づいており、従来型アプローチにおける過剰投資(赤線)と、横断活用型アプローチにおけるデータ効率(青線)を明確に対比しています。
つまり、横断活用型アプローチは、従来の非累積型機械学習に比べて、プロジェクトが増えるほどデータ利用効率の面で優位性を持つ可能性がある、ということです。
ここまで見てきた考え方を踏まえ、次に自動車業界における実践的なユースケースを紹介します。
HVACシステムの開発とAIモデルのためのデータ収集

自動車用HVACシステムとは、Heating, Ventilation, and Air Conditioning、すなわち暖房・換気・空調システムのことです。車内の温度、湿度、空気品質を制御し、さまざまな気象条件のもとで乗員の快適性と安全性を確保する役割を担います。自動車用HVACシステムは、ヒーターコア、エバポレーターコア、コンプレッサー、冷媒、ブロワーモーターなどで構成されており、これらはすべてCADやCAEでモデル化することができます。したがって、設計者の工学的予測を支援するニューラルネットワークベースのAIモデルにとって、有用なデータセットを提供できる対象でもあります。
ケーススタディ:HVACシステム
ある大手自動車メーカーに部品を供給するTier 1サプライヤーの空調制御チームが、過去5件のHVACプログラム(プロジェクト)について、設計の反復案とシミュレーション結果を保存しているとします。
設計チームや研究開発チームは、通常、各プロジェクトの中で20~40件程度の設計バリエーションを検討します。もし各チームの作業結果をすべて統合できれば、機械学習モデルの学習データとして利用できる設計案と、それに対応するCFD解析結果を、合計でおよそ150件分確保できることになります。
ただし、これら5件のHVACプロジェクトは、それぞれCADのパラメータ化が異なり、さらに対象となる車種も異なるため、トポロジーにも大きな違いがあります。
以下は従来型のアプローチで、2つのプロジェクトチームが異なる制約条件のもとで設計した内容が示されています。それぞれ異なるOEM顧客に対応する必要性などもあり、形状のパラメータ化はお互い相関しない形になっています。
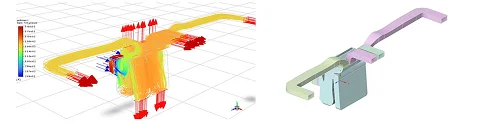
プロジェクト1
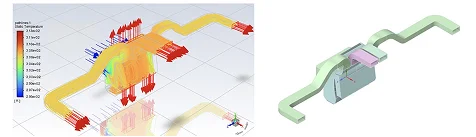
プロジェクト2
従来のパラメータ依存型機械学習はプロジェクトごとの制約条件で設計しているため、CADのパラメータ化やトポロジーがプロジェクトごとに大きく異なる
標準的なパラメータベースの機械学習アプローチでは、各プロジェクトごとに新たなサロゲートモデルを個別に構築しなければなりません。そのため、エンジニアリングチームは、同じAIモデルを次のプロジェクトにそのまま使い回すことができません。
さらに、各プロジェクトで得られる20~40件程度のCFDシミュレーションでは、精度の高いサロゲートモデルを学習させるには不十分です。その結果として生まれるのは、精度が十分でない、しかも相互に分断されたモデル群になってしまいます。
これに対して、NCSのような3D CNNベースの深層学習モデルを用いれば、各プロジェクトにまたがる複数の入力データを対象に、単一のモデル、すなわち汎用化されたサロゲートモデルを学習させることができます。この場合、利用できる約150件のデータポイントをすべて学習に活用できるため、より精度の高い予測モデルを構築でき、データ準備にかかるチームの負担も軽減されます。
さらにその後のプロジェクトにも再利用することができ、追加するデータポイントはごく少なくて済むか、追加データなしでも活用可能です。
まとめ
AIモデルを大規模に展開しようとするとき、データ収集はしばしばエンジニアリングチームにとって大きな課題なります。しかし、この技術的ユースケースが示すように、Neural ConceptのAIモデルは、自動車業界の企業がこの障害を乗り越えるうえでの道筋を示します。
機械学習が大規模データセットから大きな恩恵を受ける以上、予測モデルを学習させるために十分なデータを収集することは重要ですが、3D深層学習を活用すれば、既存のCAE資産を再利用しながら、そのハードルを大きく下げることができるのです。