コラム
日本のCAEエンジニアが乗り越えるべき壁:スキル変革と組織文化への対応
1. はじめに
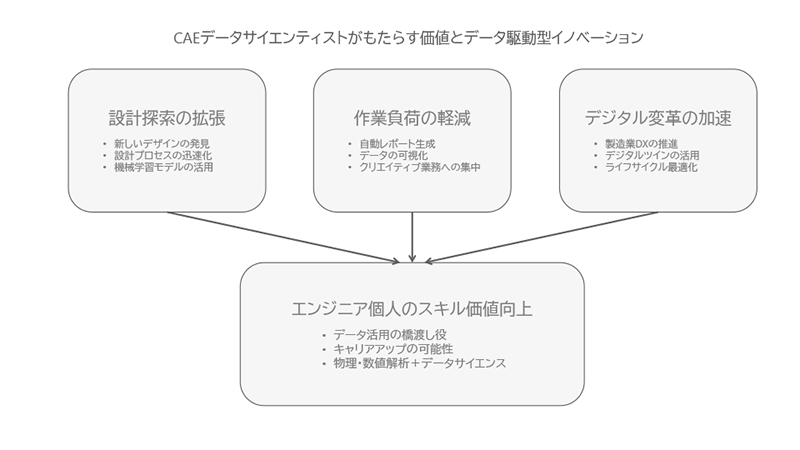
前回の第1回コラムでは、「CAEデータサイエンティスト」とはどのような役割であり、なぜ今注目されているのかを大きな視点で概説しました。
欧米では既に、CAEとデータサイエンスを組み合わせた“ハイブリッドエンジニア”が多くの企業やスタートアップで活躍し、日本国内でも徐々に興味を持つ企業が増えています。
しかし、ただ「欧米で成功しているから、日本でもそのままやればうまくいく」というわけではありません。
日本特有の組織文化や意思決定プロセス、スキルセットの差異など、乗り越えなければならない壁は少なくありません。
今回は、それらの課題を整理しながら「具体的に何をすれば解決できるのか」を考えていきます。
2. 日本のCAEエンジニアが直面する主要な課題
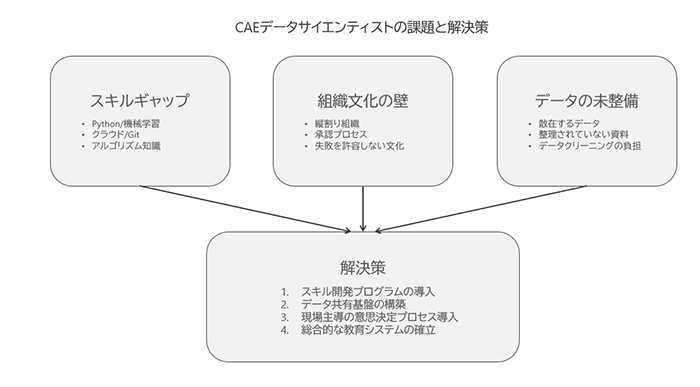
2.1 スキルギャップ:CAE×データサイエンスの融合の難しさ
CAEエンジニアの多くは、解析ソフトウェアの操作や力学・熱流体の理論に強みを持っています。
一方で、データサイエンスでは、Python等のプログラミングスキル、機械学習のアルゴリズム知識、クラウドやGitなどのソフトウェア開発に近い知識が必要です。
この「CAE」と「データサイエンス」の間にある“スキルの溝”が、日本のエンジニアにとって大きなハードルになっています。
さらに、CAEエンジニアの多くが慣れ親しんでいるのは、MATLABやGUIベースの解析ツールであり、コンソール上でPythonを使う経験が少ないケースも珍しくありません。最初のうちはエラーに戸惑ったり、コードバージョン管理が分からなかったりと、学習の初期段階で挫折する要因が潜在しています。
2.2 組織文化・意思決定の壁
日本企業の製造業では、しばしば「縦割り」「年功序列」「合意形成重視」といった文化が根強く残っています。
CAEデータサイエンティストとして新しい技術やプロセスを導入しようとしても、
- 部署間の連携の難しさ
設計部門、実験部門、IT部門などがそれぞれ独自のワークフローを持ち、データの形式や保管場所がバラバラ。 - トップダウンの承認プロセス
新技術を試すには上層部の“稟議”が必要で、検証やPoCに時間がかかりすぎる。 - 失敗を嫌う文化
「とりあえずやってみよう」というスピード感を重視しづらい雰囲気。失敗が責任問題化しやすい。
といった障壁が立ちはだかります。こうした要因が「データドリブンな試行錯誤」を阻害しがちです。
2.3 現場レベルでのデータの未整理
さらに、日本企業には「膨大なCAEデータや実験データはあるが、整備されていない状態で放置されている」ケースも多く見受けられます。ファイルサーバに無秩序に保管された過去のCAE結果、紙のレポートをPDF化しただけで検索できない技術資料など、データは存在していても活用しにくい形になっているのです。結果として、データサイエンスを始めようにも「まずはデータクリーニングだけで途方もない労力がかかる」という問題が頻繁に起こります。
(出典)筆者作成
3. CAEデータサイエンティストのワークフローと課題
こうした課題を踏まえて、CAEデータサイエンティストが実際にどのようなステップで仕事を進めていくのかを再度確認してみましょう。
ここで、ワークフローを視覚的に示すチャートをご紹介します。
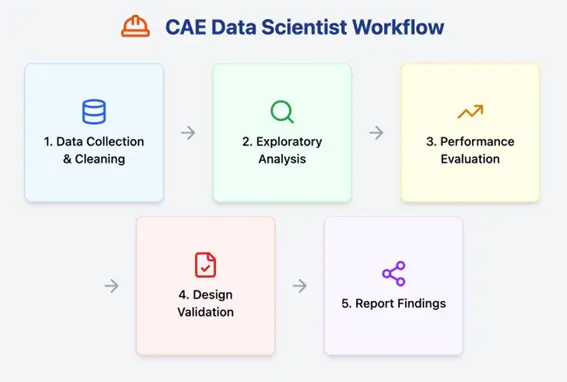
(出典)Maksym氏のLinkedIn投稿より
このチャートにあるように、大まかに5つのステップを回していくのがCAEデータサイエンティストの仕事です。
ですが、組織文化やスキルギャップの問題によって、各ステップで立ちはだかるハードルは変わってきます。
4. スキルギャップを埋めるための具体策
上記のような課題に対応するためには、CAEエンジニアとCAEデータサイエンティストのスキルギャップを埋める必要があります。
いくつかの具体策を紹介します。
4.1 PythonやMLツールの初学者向け支援
「CAEエンジニアがいきなりPythonや機械学習を学ぶのはハードルが高い」という意見があります。
しかし、昨今はオンライン学習サービスや各種コミュニティが充実しているため、短期間で基礎を習得することは十分可能です。
具体的には下記のようなものがあげられます。
- 社内勉強会の開催
CAEエンジニアが互いに学んだ内容をシェアし合う場を設け、情報格差を減らす。 - ラーニングパスの提供
Python基礎、NumPy/Pandasの基礎、機械学習の基礎、といった段階的な教材を社内ポータルで確認。存在しない場合はオンライン学習サービスで入手。 - プロトタイプでの実践学習
小さなPoC(Proof of Concept)を起こし、実際のデータを使ってみる。成功体験が得られると学習意欲が高まる。
4.2 オンラインリソースと国内コミュニティの活用
日本語での情報不足を感じる人もいるかもしれませんが、CDLEやIKIGAI lab.など国内のAIコミュニティは活発です。
勉強会やハンズオンセミナーが頻繁に開催されています。
書籍や動画コンテンツも日本語のものが増えてきました。
たとえば独立行政法人情報処理推進機構(IPA)が主催するマナビDXでは数多くの学習教材が提供されています。
SNSやQiitaなどを活用して情報収集するのも有効でしょう。
5. 組織文化へのアプローチ
5.1 小さな成功体験の積み上げ
新しい技術を導入する際に日本企業でありがちなのが、「大きなプロジェクトで一気に成果を出そうとして失敗する」パターンです。
特にデータサイエンス系は実験と失敗がつきものであり、最初から大規模に展開するとリスクも大きくなります。
そこで有効なのが、「社内外へのデモプロジェクトや部分的PoCを行い、小さな成功を積み重ねて理解と支持を獲得する」アプローチです。
例えば、CAE解析結果から自動でレポートを生成するスクリプトを作り、数時間分の作業削減を実現できれば、それだけでも十分説得材料になります。
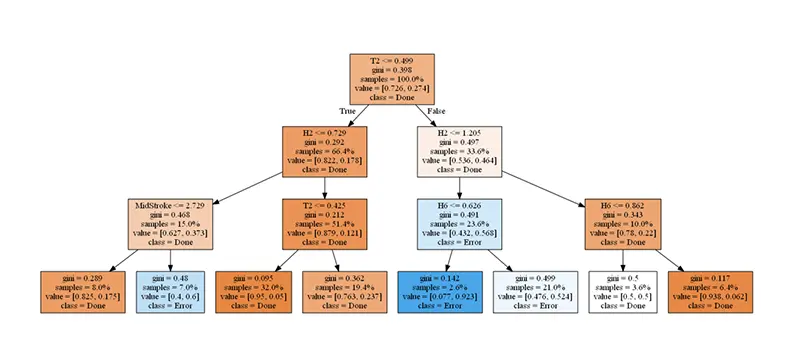
以下の事例は、CAEデータから非線形構造解析の発散可能性と設計パラメータとの関係を機械学習の一種である決定木で分析している例です。
以前であればベテランの勘と経験によるところが大きい領域でしたが、データと機械学習により、どのようなパラメータの組み合わせで発散しやすくなるかが視覚的に理解しやすくなります。機械学習としては初歩的な内容ですが、新たな視点をもたらすことでしょう。
(出典)筆者作成。scikit-learnを利用。
5.2 部門横断チーム・メンターの活用
CAEデータサイエンスは、設計部門や解析部門に加え、ITインフラを管理する部署など多岐にわたる連携が必要です。
社内の“ハブ役”を育成するためには、
• 「IT部門や情報システム部門のエンジニア」とタッグを組む
• 「過去にDX推進プロジェクトを担当したリーダーやアドバイザーに相談する」
など、部門横断で情報共有できる体制を作ることが重要です。
特に日本企業は異なる部門間の連携がスムーズではない場合が多いので、明確にチームを編成し、週次または月次で進捗を確認する仕組みを用意すると良いでしょう。
6. 組織マネジメントと経営層への説得
6.1 期待される成果を定量化する
日本企業では「投資対効果(ROI)」や「費用対効果」を明確に提示することが重要視される傾向が強いです。
データサイエンスプロジェクトを提案するときは、「どのくらいのコストがかかり、どのくらいの工数削減や品質向上が見込めるのか」をできるだけ定量化して示すことが、経営層の理解を得る近道です。
例えば、「CAE解析に要する作業時間がX%削減できる」「過去の実験結果を再活用することで年間○百万円のコスト減が見込める」といったインパクトを示せば、投資回収期間も算出しやすくなります。
6.2 リーダーシップが重要
トップダウンでないと動きにくい日本企業においては、経営陣や上級管理職のバックアップを得ることが成功要因になります。
ただし、「役員クラスは技術に詳しくないから難しい」という思い込みは危険です。
むしろ、経営的な視点を持った技術者が具体的な数値やシナリオを提示すれば、トップも興味を示しやすくなります。
リーダーを巻き込む際には、「いかに競合他社より優位に立てるか」「将来的な新規事業の可能性が広がるか」など、企業戦略と結びつけた説明が有効です。
7. 今後の展望:スキル変革は避けて通れない
CAEエンジニアがデータサイエンスのスキルを身につけ、組織全体のDXを推進していくのは、もはや避けられない流れになりつつあります。
現状の「解析専任」「データ分析専任」という分断状態を放置していては、今後の激しい市場競争に対応しきれないでしょう。
前回コラムでも触れたように、日本企業は「完璧主義的な慎重さ」と「合意形成プロセスの複雑さ」という課題を抱えています。
しかし、その一方で「底堅い品質志向」や「現場力の高さ」など、プラスに転じられる強みもあります。
スキル変革と組織文化へのアプローチを両輪で進めることで、CAEデータサイエンティストの導入は大きく加速するはずです。
8. まとめと次回予告
今回の第2回では、日本のCAEエンジニアが直面する課題と、それを乗り越えるための具体的なヒントを紹介しました。
ポイントは「スキル不足」と「組織文化」という二つの壁を同時に意識することです。
• スキルギャップを埋めるには、段階的な学習と小さなPoCによる成功体験を積む。
• 組織文化には、部門横断チームや明確なROIの提示、小規模成功事例の共有などで対応し、経営層の理解を得る。
これらの取り組みを地道に継続すれば、CAEデータサイエンスを活用したイノベーションが実現しやすくなるでしょう。
次回の第3回では、「1000時間のロードマップ:実践的CAEデータサイエンス学習のステップ」をテーマに、実際に何から学べば良いのか、どんなペースで進めるのが現実的なのか、といった内容を具体的にご紹介します。Pythonを中心とした学習フェーズや機械学習の基礎習得、さらにはCAEデータの取り扱いまで、ステップバイステップで解説する予定です。どうぞお楽しみに。