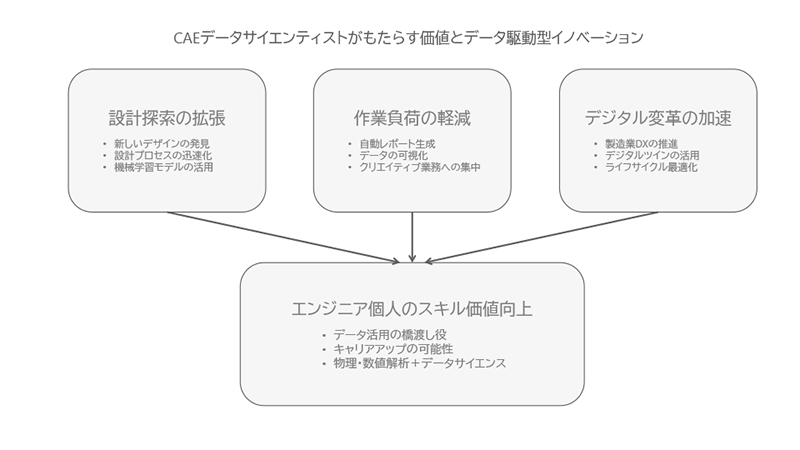
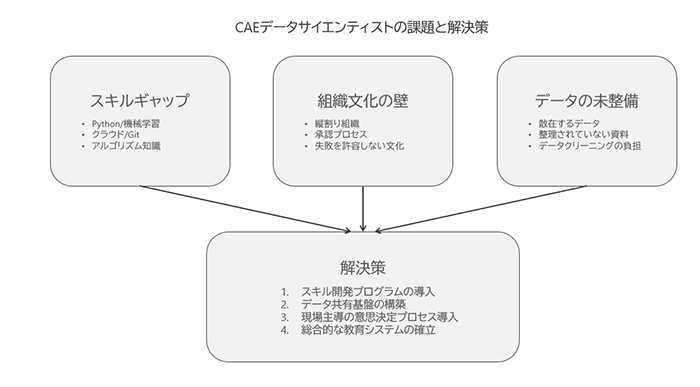
コラム
1000時間のロードマップ:実践的CAEデータサイエンス学習のステップ
1. はじめに
第1回コラムでは「なぜCAEデータサイエンティストが注目されるのか」、第2回コラムでは「日本のCAEエンジニアが乗り越えるべき課題と組織文化への対応策」を論じました。
いよいよ第3回となる本稿では、より実践的な学習方法にフォーカスします。特に、「エンジニアがどのようにデータサイエンスを学び、CAEに活かせるようになるか」という道のりを、学習時間およそ1000時間を目安としたロードマップとして提示します。
「1000時間」という数字は、Maksym氏の投稿や筆者自身の経験則から得られたおおまかな目安です。もちろん個人差がありますが、一つの指針として「ここまでの時間を投資すれば、CAEデータサイエンスの基礎を固め、実務に適用できるレベルに到達できる」という意味合いで捉えていただければ幸いです。
2. なぜ「1000時間」なのか?
2.1 コアスキル習得に必要な投資
CAEデータサイエンスを実践する上で必要なスキルは、非常に幅広い領域にまたがります。
- Pythonなどのプログラミング基礎
- 数値解析や統計の基礎
- 機械学習(回帰、分類、次元削減、ニューラルネットなど)の基礎
- CAE特有のデータ構造(メッシュ、ジオメトリ、境界条件設定など)の理解
- 可視化や実験レポート作成、シミュレーション結果比較の手法
これらを“ある程度”実務で活かせるレベルまで習得しようとすると、やはり一定の学習時間が不可欠です。
Maksym氏が自身の経験や周囲の事例を踏まえて導きだした「1000時間前後」は確保したいところです。
2.2 集中投下 vs. 分散学習
「1000時間を一気に費やすのは現実的ではない」という声もあるでしょう。
実際にフルタイム勤務しながら学習する場合、1日1〜2時間程度の勉強時間を捻出するのが一般的かもしれません。
それでも、半年から1年程度の長期視点でコツコツ続ければ十分到達可能な数字です。もちろん、まとまった期間を取れるなら、さらに効率よく学べる場合もあります。
3. ロードマップ全体像
ここでは、ロードマップを大きく3つのフェーズに分けて紹介します。
- フェーズ1:Python&数値解析の基礎学習(〜50時間程度)
- フェーズ2:機械学習の理論・実装の基礎習得(〜150時間程度)
- フェーズ3:CAE特有のデータを扱う応用ステップ(残り時間)
もちろん、各フェーズに要する時間は人によって増減がありますし、並行して学習しても構いません。
ただ、最初からCAE特有の高度な領域に手をつけるよりも、まずはプログラミングとML(機械学習)の基本を押さえておく方が結果的に効率的です。

(出典)筆者作成
4. フェーズ1:Python&数値解析の基礎(〜50時間目安)
4.1 Python未経験者が最初に取り組むこと
CAEデータサイエンスでは、Pythonを使うのが主流です。
MATLABやC++に比べて学習コストが低く、豊富なライブラリが揃い、コミュニティも活発だからです。
4.2 学習環境とツール
- Jupyter Notebookや Visual Studio Code (VSC)など、自分が使いやすい開発環境を整える。
- GitHubやGitLabで学習の成果物を管理しておくと進捗が把握しやすい。
- 環境構築が難しい場合は、最初はGoogle Colaboratoryのようなサービスを使うと簡単。
4.3 演習のすすめ
フェーズ1の段階は、「手を動かして慣れる」ことが最も重要です。
教科書的なサンプルコードを動かしてみるだけでなく、できれば簡単なスクリプトを書いてみましょう。
- CSVファイルを読み込んでグラフ化する
- Excelで管理していたCAE結果をPandasで集計する
- NumPyで行列演算や線形回帰の実装にトライする
こうした簡単な演習を通じて、Pythonを使うのが自然と当たり前に感じられるようになるのを目指します。
5. フェーズ2:機械学習の基礎理論と実装(〜150時間目安)
5.1 なぜ機械学習が必要か
CAEは基本的に物理モデルに基づくシミュレーションです。一方、機械学習は過去のデータからパターンを学習し、将来を予測したり分類したりする手法です。
「シミュレーション結果が大量にある」「実験データも蓄積されている」「設計パラメータの最適化を高速化したい」などの課題に対して、ML技術は強力な武器となります。
また、CAE解析結果を効率的に可視化・評価するためのデータ分析スキルは、組織内で非常に重宝されるでしょう。
5.2 学習対象となる主要アルゴリズム
機械学習と一口に言っても範囲は膨大ですが、以下の基礎アルゴリズムを押さえることでCAEへの応用もしやすくなります。
深層学習(ディープラーニング)を扱いたい場合も多いでしょうが、まずは上記の伝統的アルゴリズムを身につけることが、CAEデータサイエンスの初期段階では有用です。
5.3 おすすめ教材と学習スタイル
5.4 150時間の学習イメージ
1日2時間×3ヶ月程度を目安とすれば、理論学習と簡単な実装演習を一通りこなせる計算です。
演習を繰り返すことで、ハイパーパラメータ調整やデータ前処理のノウハウが少しずつ身についていきます。
6. フェーズ3:CAE特有のデータを扱う応用ステップ(残り時間)
6.1 PyVistaなど3Dデータ解析ツールの習得
CAEデータサイエンスの醍醐味は、3D形状データやメッシュを直接扱う点にあります。PyVistaやVTKなどのPythonライブラリを使えば、シミュレーション結果の可視化やメッシュ操作をプログラム的に実行できます。
こうした処理を自動化し、膨大な設計案や解析結果を一括で比較・整理する仕組みを作れるのが、CAEデータサイエンティストの強みです。
6.2 応用的なサロゲートモデルや最適化手法
6.3 実務プロジェクトへの応用
最終的に、こうしたCAE特有の応用テクニックを活かして「実際の製品開発に貢献するシステム」を作るのがゴールです。例えば、自動車部品の形状最適化や航空機エンジンブレードの流体解析サロゲートモデル構築など、現場の課題に即したプロジェクトで学習内容を定着させます。
この段階まで到達するには、フェーズ1・2で培った基礎力が必須なので、焦らず順を追って進めることが大切です。
7. CAEのためのPythonラーニングパス
ここで、全体の学習ステップを整理したチャートをご紹介します。
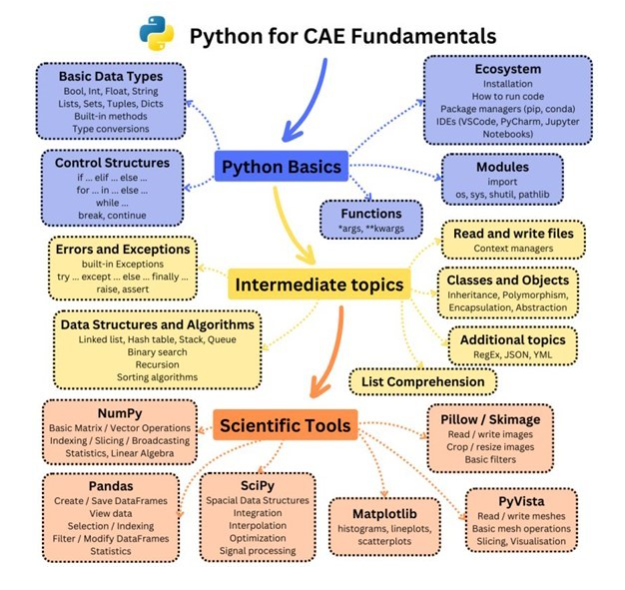
(出典)Maksym氏のLinkedIn投稿より
Pythonの基本から、NumPy/Pandas、Plotlyなどのライブラリ、さらにPyVistaのような3D可視化・操作までをざっくりとマップ化しています。
これにより学習の優先度や関連性がひと目でわかると思います。
8. ポイント:学習計画の立て方とモチベーション維持
8.1 具体的な目標設定と小さな成功体験
学習時間を確保する上で重要なのは、「何のために学ぶのか」という明確な目的設定です。漠然と「CAEデータサイエンスをやりたい」だけでは、忙しい日常に流されてしまいます。
- 「3か月後にPythonで解析結果を自動レポート化できるようにする」
- 「半年後に最適化アルゴリズムを実装し、設計案数十種類を自動評価するシステムを社内デモする」
こうした小さな目標を複数設定し、達成したらチーム内でシェアしたり上司に報告することでモチベーションを高められます。
8.2 コミュニティの活用
8.3 失敗から学ぶ姿勢
機械学習やCAEの分野では「試してみたけど思ったより精度が出ない」「データがうまく扱えずエラーだらけ」などの“失敗”が当たり前です。そうした失敗を積み重ねてノウハウを得るのがデータサイエンスの本質ともいえます。あまり完璧主義に陥らず、「どこがボトルネックなのか」を楽しみながら探求する柔軟なマインドが、長期的な成長につながります。
9. まとめと次回予告
本コラムでは、1000時間を目安としたCAEデータサイエンス学習のロードマップを提示しました。
- フェーズ1(〜50時間):Python基礎&数値解析ライブラリ
- フェーズ2(〜150時間):機械学習の基礎理論と実装
- フェーズ3(残り時間):CAE特有の応用(3Dデータ処理、サロゲートモデル、最適化など)
焦りすぎず、しかし確実にステップを踏めば、半年から1年のスパンでエンジニアとしての新たな武器を手に入れることが可能です。第1回・第2回で触れた通り、組織文化や社内調整の課題も確かに存在しますが、今回ご紹介したロードマップをもとに着実にスキルを積み上げれば、説得材料やPoCの成功体験が得やすくなるはずです。
次回のコラム(第4回)では、「社内での影響力を高める:CAEデータサイエンティストとしてのキャリア戦略」をテーマに、習得したスキルをどのように組織の中で活かし、自身のキャリアを広げていくかを解説する予定です。学んだはいいが評価されない、うまく活用されないという悩みを持つ方に向けて、具体的なアクションプランを提案しますので、ぜひご期待ください。