2016.11 テキストビッグデータから何を読むか
技術に関する膨大な量のテキストのビッグデータから「何を向上させようとしているか」という目的を抽出し、開発のトレンド等を分析したいとき、どのようにするでしょうか?
このようなビッグデータの分析では「データの前処理がその分析の8割を占める」といわれるほど前処理が重要視され、最も時間を要するところです。
例えば、ビッグデータ分析の自動化に関連する最新の研究でも、ラベリングやセグメンテーションなどの「前処理」が自動化の大きな鍵となっているようです(※1)。
「データの前処理」は、分析するためにビッグデータを構造化する行為だと言えます。そしてその「構造化」によって利用できる分析手法が左右されるので、重要視されるのも当然でしょう。
さて、社内やインターネット上には膨大なテキストデータがあります。それらテキストには人間の思考・目的・アイデアや、経験やデータから検討された結論や意見などが含まれています。これらは大変に内容の濃い情報です。
このような「テキストビッグデータ」の分析でも、当然「前処理」の問題があります。
例えば「頻繁に分析されるテキストビッグデータ」とも言える特許情報は、タイトルや権利者、発効日や特許コードのように「構造化」されており、実施される分析もその「構造」に従ったものになります。
また、キーワード検索やデータマイニング手法も利用されるので、単語レベルに分けた構造化もなされています。
しかし、意見やアイデア等は「文」で表現されるので、キーワードレベルの分析では「意見や目的やアイデア」を抽出するのはなかなか難しく、予測や推測が必要になってきます。
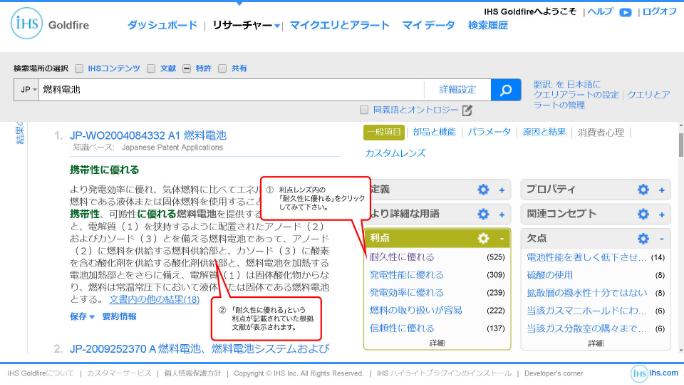
一方、Goldfireは文の構造まで分析しています。
つまり、膨大なテキストビッグデータから「意見や目的やアイデア」を抽出しやすいよう、テキストビッグデータを「前処理」している訳です。更にそれだけではなく、膨大な情報を利点・欠点・応用・方法などにカテゴライズします。
さて、冒頭の問いに対してですが、Goldfireでは「向上」と入力するだけで分析のための情報を抽出することができます。実際に、ここ20年程度について特許(※2)を対象にして行ってみると、向上させている上位3つは「信頼性、生産性、耐久性」であり、20年間ほとんど変わっていません。
逆に「画質、測定精度、歩留まり」等は順位が下がってきています。そして、「ユーザーの利便性、意匠性、メンテナンス性、視認性」等がここ20年間で徐々に上位に上がってきています。また「耐熱性、密着性」というワードも常に上位にあります(Goldfireを利用すれば更に、それが「何の耐熱性なのか」「何の信頼性なのか」という情報まで抽出可能です)。
ここから何を読み取るかは人間の仕事ですが、ここまでの作業にかかった時間は40分足らずなので、考える時間はたっぷりあります。
ビッグデータに対する適切な前処理は、実施したい分析により変わります。
「テキストビッグデータから意見や目標やアイデアの情報を抽出して気付きを得たい」そんなときは、Goldfireに聞いてみるとスムーズ、かもしれません。
※1:Automating big-data analysis|MIT News
※2:Goldfireの特許知識ベースの中でJapanese Patent Applicationsを対象にしています。
▼今回使ったGoldfireの機能は...▼
ナレッジナビゲーター
Goldfireとは?
イノベーションをより「起こしやすく」する。Goldfireは、そんな環境を構築できるソフトウェアです。普段気づかない知識を知りたい・他業種での利用方法や技術情報を知りたい・原因特定や問題解決を効率よく行いたい・培った技術や知識を組織内で幅広く共有したい、こんなお悩みをお持ちの方はまずはGoldfireの製品紹介のページをご覧ください。
イノベーションが「起こりやすく」なる状況とは?
次のような状況を満たした環境があれば、イノベーションへのプロセスは加速されるはずです。
- 社内・社外の広範な知識を素早く収集することができる
- 面白いアイデアを豊富に出すことができる
- 問題・テーマについて、検討や意思決定をよりロジカルに行える
- 結果はもちろん「検討過程」についても関係者で共有し活用できる
広範な知識を集めて「アイデア」の生成を支援するソフトウェア
様々な企業が「Goldfire」を活用しています
- AGC株式会社
- 味の素株式会社
- キユーピー株式会社
- サントリーグローバルイノベーションセンター株式会社
- 住友精化株式会社
- 株式会社ダイセル
- DIC株式会社
- 株式会社デンソー
- パナソニック株式会社
- 株式会社富士通研究所
- 藤森工業株式会社
- 株式会社牧野フライス製作所
- 三菱自動車工業株式会社
| Goldfire 製品情報 | イノベーションをより「起こしやすく」するイノベーションプラットフォーム「Goldfire」について詳しくご紹介します。 |
|---|---|
| ものづくりイノベーション支援 | ものづくりのイノベーションを支援するコンサルティングやトレーニングなど、総合的なサービスについてご紹介します。 |
| 顧客事例 | Goldfireは、全国さまざまなお客様にご活用いただいており、国内外の顧客事例をご覧いただけます。 |
| セミナー・イベント | Goldfireを直接体験できるセミナーをはじめとする、Goldfireに関するセミナーやイベント出展に関するトピックをご案内しております。 |